_220314_ 210317 210316 [ √ ] install Termux on my Android smartphone [PERSONAL] [PROJECT] [TO-DO] [7]
210317 [ • ] read through the 'to-do' tutorial a second time [TO-DO] [5]
210317 [ • ] do a search for the Linux 'copy' command [TO-DO] [6]
In the past year -- just recently, really -- I've found a way to tie-in my prior 'universal paradigm' (scientific method) framework into this daily-text-file to-do thing / approach....
(Note that the sample three lines of the to-do list above have been 'updated', with the check mark for a completed item, and a bullet character for the 'otherwise finished' two items. I also added the 'done' date for the first item by enclosing it, 220314, within _underscore_ characters. This process can be used to designate *any* 'completed' information to add-in after an item is finished and closed-out.)
(Also be sure to add in new items *at the top*, to push the already-existing content *downwards*, sorting the lines as desired, in groups of lines, with decreasing importance / priority going downward through the text file. I like to keep a little 'protected' area at the very top for *time-sensitive* *calendar* items, with a '---' divider right underneath.)
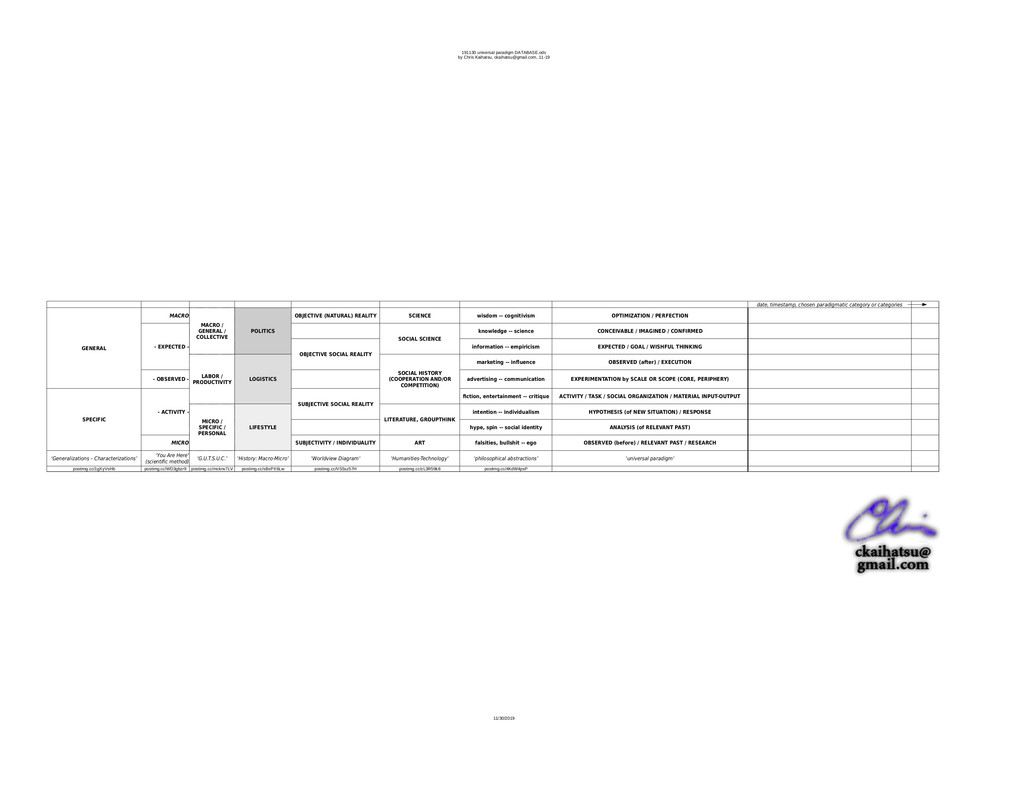
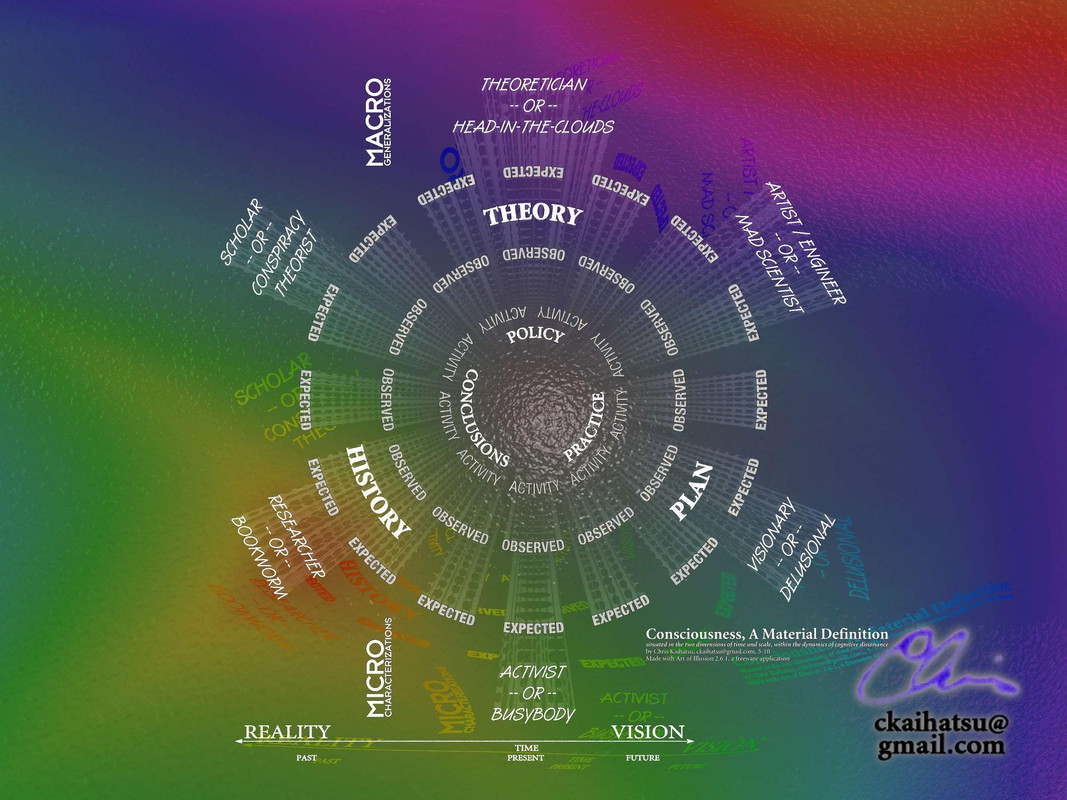
So here's how to make similar 'data entries' to a to-do-list-like *other* text file, maybe named 'YYMMDD_index', or by project name, or whatever. Note the nine categories in the 'universal paradigm' taxonomy in the graphic below, and the shortened 'nicknames' they correspond to in the sample text entries:
_______________________________________________________________________________
220307 sample entry
____________________________________________________YYMMDD-AND-NOTE-NAME IF ANY
DSC_1459.JPG
_____________________________________________SOURCE PHOTO IMAGE FILENAME IF ANY
1PAST|2YESNO|3AND?|4TASK|5TRY|6GOOD?|7WOULD|8SHOULD|9BEST|0
_______________________________________________________________________________
220304 [ ] digital housekeeping
____________________________________________________YYMMDD-AND-NOTE-NAME IF ANY
_____________________________________________SOURCE PHOTO IMAGE FILENAME IF ANY
1PAST|2YESNO|3AND?|4TASK|5TRY|6GOOD?|7WOULD|8SHOULD|9BEST|4
_______________________________________________________________________________
220304 [ ] update music on smartphone
____________________________________________________YYMMDD-AND-NOTE-NAME IF ANY
_____________________________________________SOURCE PHOTO IMAGE FILENAME IF ANY
1PAST|2YESNO|3AND?|4TASK|5TRY|6GOOD?|7WOULD|8SHOULD|9BEST|4
_______________________________________________________________________________
220304 PHYSICAL PROJECT
linked rods for perimeter -- star dome
____________________________________________________YYMMDD-AND-NOTE-NAME IF ANY
_____________________________________________SOURCE PHOTO IMAGE FILENAME IF ANY
1PAST|2YESNO|3AND?|4TASK|5TRY|6GOOD?|7WOULD|8SHOULD|9BEST|4
Once entered, all data can be 'grep'-ed for, as detailed in that post on this thread from a year ago.
If one was looking for all 'tasks', for example, one could do a cat 220314_index | grep -B 8 '4$' | grep -B 1 -A 8 '^[0-9].*$'
to get all of the entries, in their entirety, for all entries that have a code of '4' -- which is 'task', or 'activity / task / social organization / material input-output', from the 'universal paradigm' template.
The command says 'cat', or *print* the file '220314_index', to the screen, then 'grep' / retain *only* any lines that *end* with a '4'. The dollar sign means 'the end of any given line'. Also *8* lines *before* the selected ('4'-containing) line will be included, due to the -B 8 flag / option that's included in the grep command.
Here's the thing, though -- that number of *8* lines, for any given entry (multiple lines), is somewhat *arbitrary*. Sure, it certainly *looks* as though the entries will all be *about* 8 lines long, or maybe more-like around *6* lines long, judging from the sample entries above. If any entry, at any time, happened to be *less* than 8 lines, then this command would be less-than-appropriate and might reel-in *more* than the lines of just one desired entry at-a-time -- lines from the *previous* entry might be inadvertently included, which would *not* be good.
Okay, to recap, we've 'streamed' all the data entries from the 220314_index file, using the 'cat' command. We've used grep to find the 'code' number, per entry, from the taxonomy of 1-through-9 -- in this case, we're looking for a '4' from any and all entries in the text file that *have* a code of 4, and *no others*. We're also indicating that we want the preceding *8* lines above that '4'-line matched line to be included as well, since those lines are presumably with the whole entry itself.
The *problem* now is how to *limit* the multiple-lines-selection process to *just* the lines of the '4'-coded entries, so that we get those entries, and nothing else -- nothing from the *preceding* entry, which may not necessarily be a '4'-coded entry.
The rest of that (Bash) command is *another* grep command to 'cap-off' the 'top' of the entry / -ies we've found with the *first* grep command, that itself could identify the '4'-code line *only*, and then we rather-arbitrarily included a set *8* lines of content *above* the '4' line, even though we don't actually know that any searched-for entry will *be* exactly 9 ( 1 + 8 ) lines long in the text file.
So that *second* grep command is saying 'From the preceding stuff that's incoming (all of the '4'-coded lines, plus 8 additional lines *above* each '4' line), now search for any line that begins with a *number* (0-9), and also include one line before that 'digit-starting' line, plus *8* lines *after* it. The caret symbol means 'the start of any given line', and the period and asterisk mean 'zero or more characters of any kind', until the *end* of the line (the dollar sign symbol).
These two grep commands effectively find the *bottom* end of all desired entries ('4'), up through the *top* line of (only) those found entries (which begins with a digit, for the entries' YYMMDD date number), plus the '______' divider line *above* that date number, whatever it is. I put in an '8' as a good rough parameter to use, but if *your* entries happen to vary much in number-of-lines then this parameter may need to be adjusted.
Similarly the grep commands could be altered, to maybe look for all 'done' items, by looking for a *check mark* ('√'), or an 'x', or a bullet character, or for *all* of them -- see last year's introductory post for how to do this kind of multiple-criteria kind of search.
Of course, as before, one may want to spin-off '.999' files, to receive cut-and-pasted 'done' entries out of the main YYMMDD_index file, for 'YYMMDD.999_index' files, while updating the *main* YYMMDD_index file for each new day.
universal paradigm SLIDES TEMPLATE
universal paradigm DATABASE


")




")




 - By wat0n
- By wat0n - By Tainari88
- By Tainari88 - By QatzelOk
- By QatzelOk